
Por qué tu WordPress necesita una infraestructura nativa de IA: el salto de hosting tradicional a Platform Engineering
El problema real: la infraestructura como cuello de botella
Después de años optimizando sitios WordPress y administrando servidores dedicados (WHM/cPanel, Docker, OpenLiteSpeed), el patrón se repite: las tiendas que intentan escalar terminan atrapadas en problemas de infraestructura en lugar de enfocarse en su negocio.
Los síntomas son siempre los mismos:
- Caídas durante picos de tráfico (Cyber Monday, lanzamientos, campañas de ads).
- TTFB de 800 ms a 2 s que destruyen las conversiones y el SEO.
- Costos de hosting que crecen linealmente con el tráfico, sin economía de escala.
- Imposibilidad técnica de integrar capacidades de IA porque la base de datos y la arquitectura no están preparadas.
El cambio de paradigma es claro: ya no se trata de tener un servidor más grande, sino de pasar de una arquitectura monolítica gestionada manualmente a una plataforma orquestada, contenerizada y nativa de IA.
De administrador de sistemas a Platform Engineering
La ingeniería de plataformas (Platform Engineering) es la disciplina que absorbe toda la complejidad de infraestructura, observabilidad, seguridad y despliegue, y la expone al equipo de negocio a través de golden paths: plantillas preconstruidas, seguras y optimizadas que eliminan la fricción técnica.
En la práctica, esto significa entregarte un stack donde no necesitas configurar Nginx, ajustar PHP-FPM, dimensionar MySQL, ni decidir entre Redis u otro object cache. La plataforma lo resuelve por defecto.
El servicio se estructura en un modelo de tres capas:
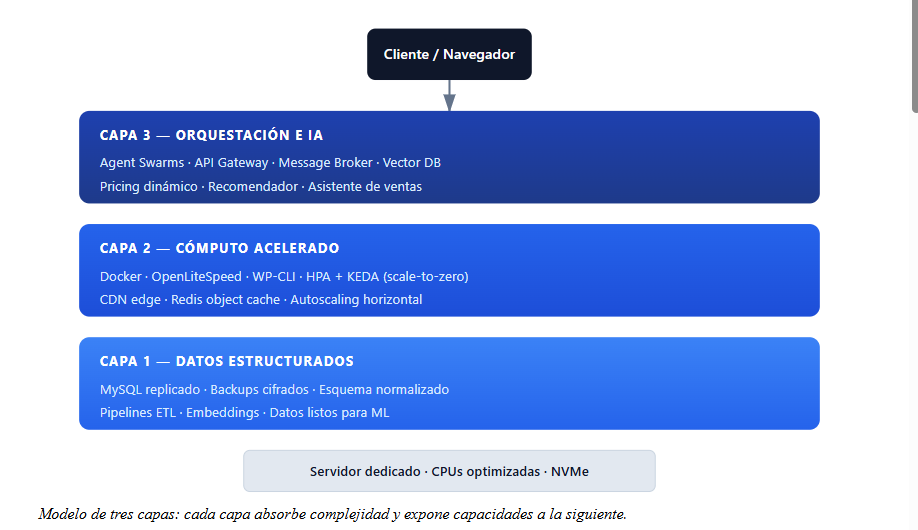
Capa 1: datos estructurados, la base no negociable
Un modelo de IA es tan bueno como los datos que consume. La mayoría de los WordPress que veo tienen la base de datos como un dumping ground: meta_keys duplicados, taxonomías desordenadas, productos sin SKU consistente, atributos globales mezclados con atributos locales.
Cualquier intento de inteligencia sobre esa base produce ruido. Lo que hago en esta capa:
- Auditoría y normalización del esquema: limpieza de
wp_postmeta, deduplicación de atributos, consolidación de taxonomías (product_cat,product_tag,pa_*), corrección de SKUs padre en productos variables. - Cifrado en reposo y en tránsito: TLS 1.3 obligatorio, cifrado de columnas sensibles (datos de cliente, direcciones, métodos de pago tokenizados).
- Replicación read/write: separación de réplicas para consultas analíticas y consultas transaccionales. WordPress nunca debe consultar tu modelo predictivo en la misma conexión que sirve un checkout.
- Pipelines ETL hacia un Vector Store: los productos, descripciones y comportamiento de cliente se vectorizan (embeddings) y se almacenan en una base vectorial (pgvector, Pinecone, Qdrant). Esto es lo que permite recomendaciones semánticas reales, no las del plugin de turno.
Sin esta capa correctamente construida, todo lo que viene después es marketing.
Capa 2: cómputo acelerado y auto-escalado a cero
Aquí es donde la mayoría de proveedores de hosting se quedan. Te venden un VPS, un Kubernetes «managed» o un plan WordPress y te cobran el pico todo el mes.La aproximación correcta es contenerizar WordPress como una aplicación stateless y delegar el estado a servicios especializados. Los archivos de medios van a almacenamiento de objetos (S3-compatible o Cloudinary, según el caso), las sesiones a Redis, la base de datos a un servicio replicado. Una vez que WordPress es stateless, escalar horizontalmente es trivial.
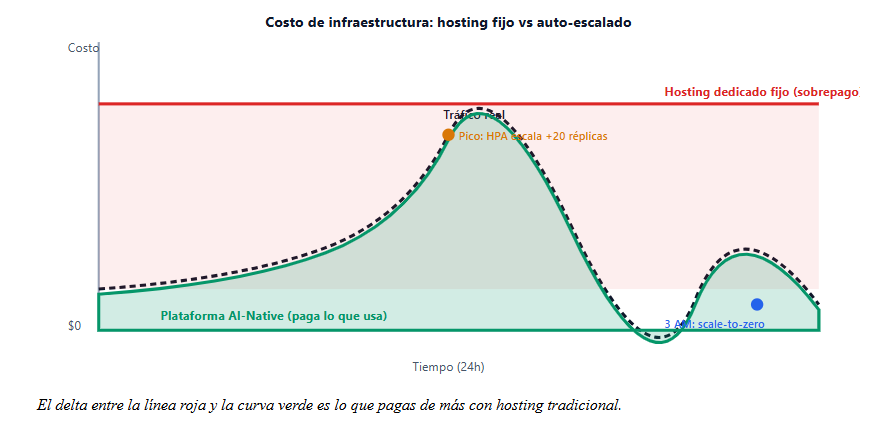
Capa 2: cómputo acelerado y auto-escalado a cero
Los componentes técnicos:
- Contenedores Docker con imágenes optimizadas (PHP 8.3 + OPcache + JIT habilitado, OpenLiteSpeed o FrankenPHP según el caso).
- HPA (Horizontal Pod Autoscaler) sobre métricas de CPU, memoria y RPS.
- KEDA para escalar a cero cuando el tráfico cae bajo un umbral, manteniendo solo un pod de «guardia» o despertando bajo demanda.
- CDN con cache en edge (Cloudflare, BunnyCDN) para HTML cacheable, assets estáticos e imágenes con transformación on-the-fly.
- Redis como object cache (drop-in replacement vía plugin) y como almacén de sesiones.
El resultado típico que mido en clientes: TTFB bajo 200 ms en P95, reducción de 40-60% en costos mensuales de infraestructura, y capacidad de absorber picos de 10-20x sin intervención manual.
Capa 3: orquestación y enjambres de agentes
Con las dos capas anteriores resueltas, recién ahora tiene sentido hablar de IA. Un agent swarm es un conjunto de agentes autónomos que cooperan para resolver tareas de negocio, comunicándose vía un broker de mensajes y consultando estado a través de APIs bien definidas.
En un WooCommerce típico, los agentes que más impacto generan son:
 Ejemplo concreto: el ciclo de una venta optimizada por agentes
Ejemplo concreto: el ciclo de una venta optimizada por agentes
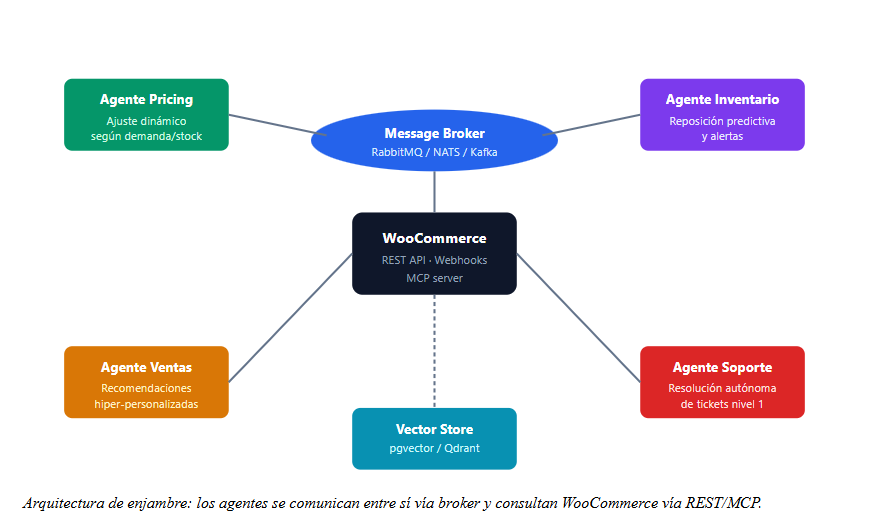
Vamos a aterrizar esto con un caso real. Cliente recurrente entra al sitio, navega tres categorías y abandona. Esto es lo que ocurre, en milisegundos, sobre la plataforma:
Lo crítico: el agente trabaja sobre una réplica de lectura y publica el resultado a través de un canal asíncrono (email transaccional, notificación push, banner inyectado vía JS). El render de WordPress no se ve afectado porque el agente no comparte hilo de ejecución con el request HTTP del cliente.
Comparativa directa: hosting tradicional vs plataforma AI-Native
| Aspecto | Hosting tradicional / Dedicado clásico | Plataforma AI-Native |
|---|---|---|
| Modelo de costo | Fijo mensual sobre el pico estimado | Variable según uso real, scale-to-zero |
| Picos de tráfico | Caída o degradación; intervención manual | HPA + KEDA absorben automáticamente |
| Despliegue | FTP/SSH manual, riesgo en producción | CI/CD declarativo, rollback en segundos |
| Datos | Esquema sin gobernanza, plugins encima | Normalizado, replicado, vectorizado |
| Capacidad de IA | Plugins SaaS de terceros, datos fuera de tu control | Agentes propios, datos en tu infraestructura |
| Observabilidad | Logs en disco, sin métricas estructuradas | Stack OTel/Grafana/Prometheus completo |
| Time-to-market | Semanas por feature de infra | Golden paths, días o menos |
Stack técnico de referencia
Para ser concreto, el stack que despliego en proyectos donde el cliente requiere capacidades AI-Native:
- Runtime: Docker + Docker Compose para entornos pequeños; Kubernetes (k3s o managed) cuando el volumen lo justifica.
- Web server: OpenLiteSpeed con LSCache, o FrankenPHP para casos donde se necesita HTTP/3 nativo y worker mode.
- PHP: 8.3+ con OPcache, JIT activado, preload del core de WordPress.
- Base de datos: MariaDB/MySQL con configuración tuneada (innodb_buffer_pool, query_cache desactivado a favor de Redis), réplica de lectura dedicada para analytics.
- Cache: Redis para object cache y sesiones; Cloudflare/BunnyCDN para edge.
- Almacenamiento de medios: S3-compatible (Wasabi, R2, Backblaze B2) o Cloudinary para transformación on-the-fly.
- Vector DB: pgvector cuando ya hay PostgreSQL; Qdrant en proyectos dedicados de búsqueda semántica.
- Broker: RabbitMQ para colas tradicionales; NATS cuando se requiere baja latencia y pub/sub masivo.
- Orquestación de agentes: implementaciones sobre MCP (Model Context Protocol) cuando el agente necesita acceso estructurado a WooCommerce, o frameworks tipo LangGraph/CrewAI para flujos multi-agente.
- Observabilidad: OpenTelemetry → Grafana + Loki + Tempo + Prometheus.
- CI/CD: GitHub Actions o GitLab CI con despliegues blue-green.
Qué obtienes al delegar la plataforma
El argumento de fondo es simple: las organizaciones que intentan construir esto internamente se quedan atrapadas en la fase de experimentación. Contratan un DevOps, después un MLOps, después intentan integrar agentes y descubren que la base de datos no está lista. Mientras tanto, los costos crecen y el roadmap de producto se detiene.
Al delegar la plataforma obtienes:
- Un stack que antes solo estaba al alcance de equipos de ingeniería de gran tamaño.
- Un único responsable técnico desde el servidor hasta los agentes.
- Predictibilidad de costos con economía de uso real.
- Capacidad real de competir contra players con presupuestos diez veces mayores.
Conclusión
El hosting dedicado fue la respuesta correcta hace diez años. Hoy es solo una pieza más de un puzzle más grande. Si tu WooCommerce factura volumen suficiente para que la diferencia entre un TTFB de 800 ms y uno de 200 ms se traduzca en miles de dólares de conversión adicional, el cálculo es directo: la inversión en una plataforma AI-Native se paga sola, y abre la puerta a capacidades que tus competidores aún están evaluando.
Si estás evaluando este salto, conversemos. Reviso tu stack actual sin compromiso y te entrego un diagnóstico con la ruta de migración recomendada.
Recommended Posts

El WordPress más rápido del mundo.
4 diciembre, 2020

Trucos y secretos de marketing digital durante el COVID-19
23 junio, 2020
